The risk of bias in hate speech detection
- 5 minsThe Risk of Bias in Hate Speech Detection
Based on Sap et al., 2019
As social media platforms continue to grow, so does the volume of toxic and hateful content online. To manage this at scale, platforms increasingly rely on machine learning models to automatically detect hate speech and abusive language.
But what if these systems are not neutral?
What if the very data used to train them embeds racial bias — and the models simply learn and amplify it?
This post discusses the paper:
Sap et al., 2019 — “The Risk of Racial Bias in Hate Speech Detection”
and explores how racial bias can enter hate speech detection systems — and what we might do about it.
The Core Problem
Hate speech detection typically follows this pipeline:
- Collect data (tweets, posts, comments)
- Ask human annotators to label the data (hate / offensive / none)
- Train a machine learning model
- Deploy the model for automated moderation
The assumption is that this process produces an objective system.
However:
- Toxicity depends on social context
- Dialect and speaker identity matter
- Human annotators bring their own biases
If the annotations are biased, the model trained on them will also be biased.
A Motivating Example: PerspectiveAPI
Tools like Google’s PerspectiveAPI assign toxicity scores to text. But prior research has shown that phrases in African American English (AAE) are sometimes rated as more toxic than their white-aligned equivalents — even when they are not intended to be offensive.
This raises a critical concern:
If annotators are unfamiliar with a dialect, they may label it as offensive simply because it sounds unfamiliar. Bias can enter before the model is even trained.
The Paper’s Hypotheses
Sap et al. investigate three main questions:
- Do existing hate speech datasets contain racial bias?
- Does this bias propagate into trained models?
- Does providing annotators with dialect/race information change their judgments?
Methodology Overview
1. Using Dialect as a Proxy for Race
Since Twitter does not typically include self-reported race, the authors use a model (Blodgett et al., 2016) to estimate whether a tweet is written in:
- African American English (AAE)
- White-aligned English
The model assigns probabilities:
pAAEpWhite
This allows researchers to analyze patterns across dialect groups.
2. Testing Bias in Existing Datasets
The authors examine two widely used hate speech datasets:
- DWMW17 (Davidson et al., 2017)
- ~25K tweets
- Labels: hate speech, offensive, none
- FDCL18 (Founta et al., 2018)
- ~100K tweets
- Labels: hateful, abusive, spam, none They analyze the correlation between AAE probability and toxicity labels.
Key Finding:
Tweets more likely to be written in AAE were significantly more likely to be labeled offensive or abusive. 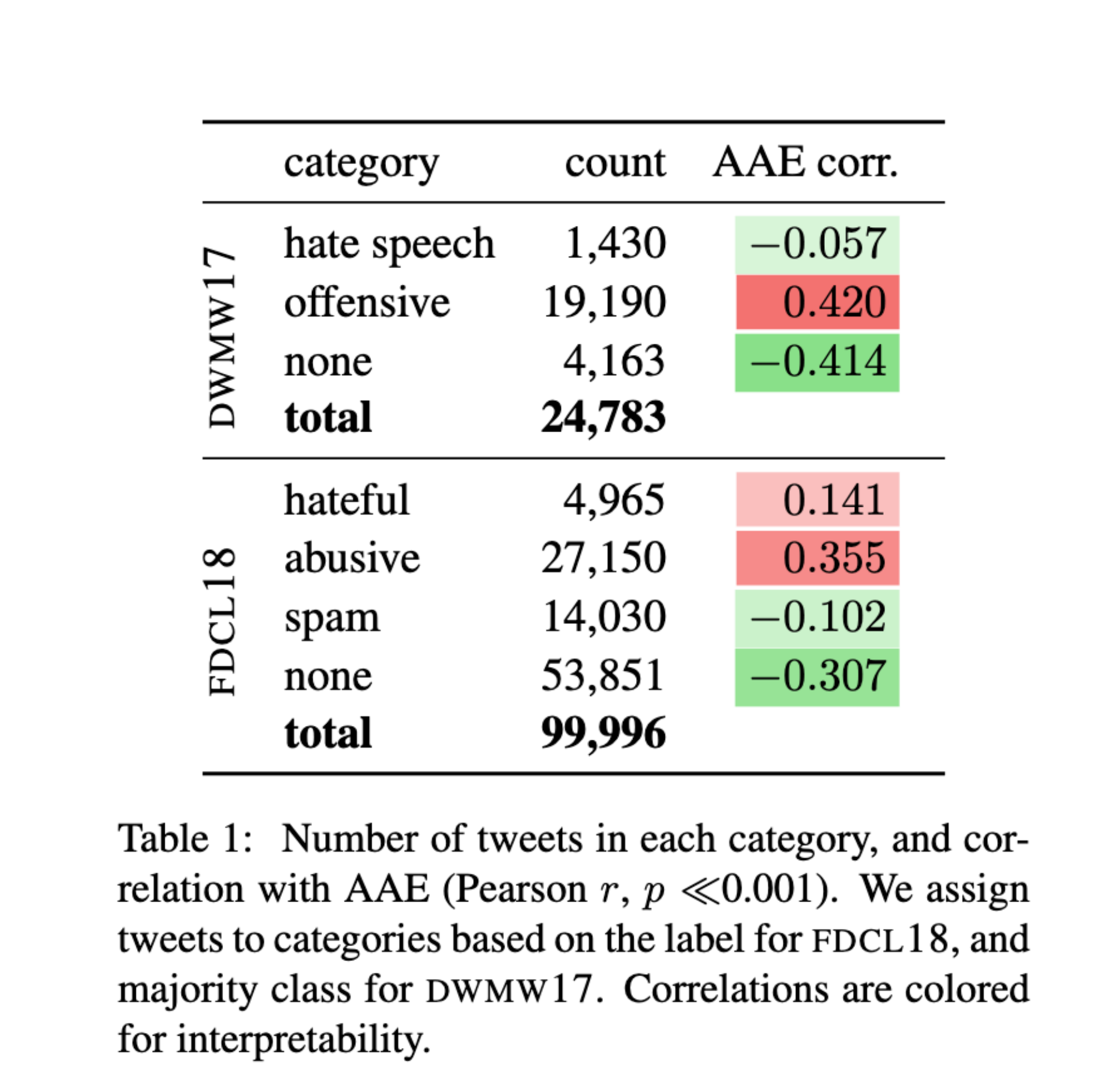
This suggests that bias may already exist in the labeled data.
3. Bias Propagation Through Models
Next, the authors train classifiers on these datasets and evaluate:
- False positive rates across dialect groups
- How often non-toxic AAE tweets are misclassified as toxic
Result:
Models trained on these datasets showed higher false positive rates for AAE tweets compared to white-aligned tweets.
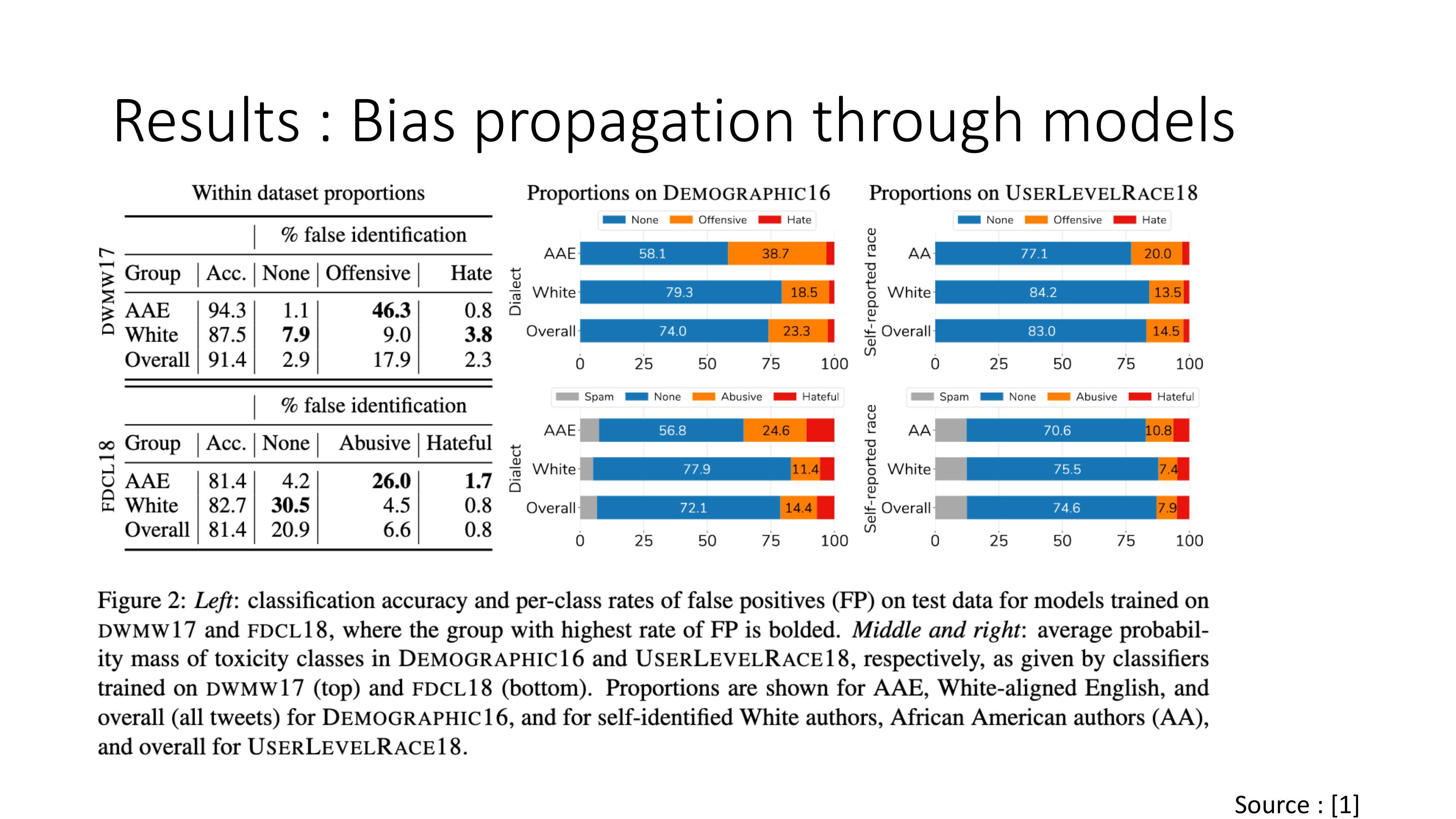
In other words:
Even when AAE tweets were not offensive, they were more likely to be flagged as such.
This demonstrates how dataset bias propagates into deployed systems.
4. Does Context Change Annotations?
The authors ran a controlled experiment on Amazon Mechanical Turk.
Workers were asked whether tweets were:
- Offensive to them
- Offensive to anyone
Three conditions were tested:
- Control (no dialect information)
- Dialect priming
- Race priming
When annotators were encouraged to consider dialect and likely racial background:
- AAE tweets were significantly less likely to be labeled offensive.
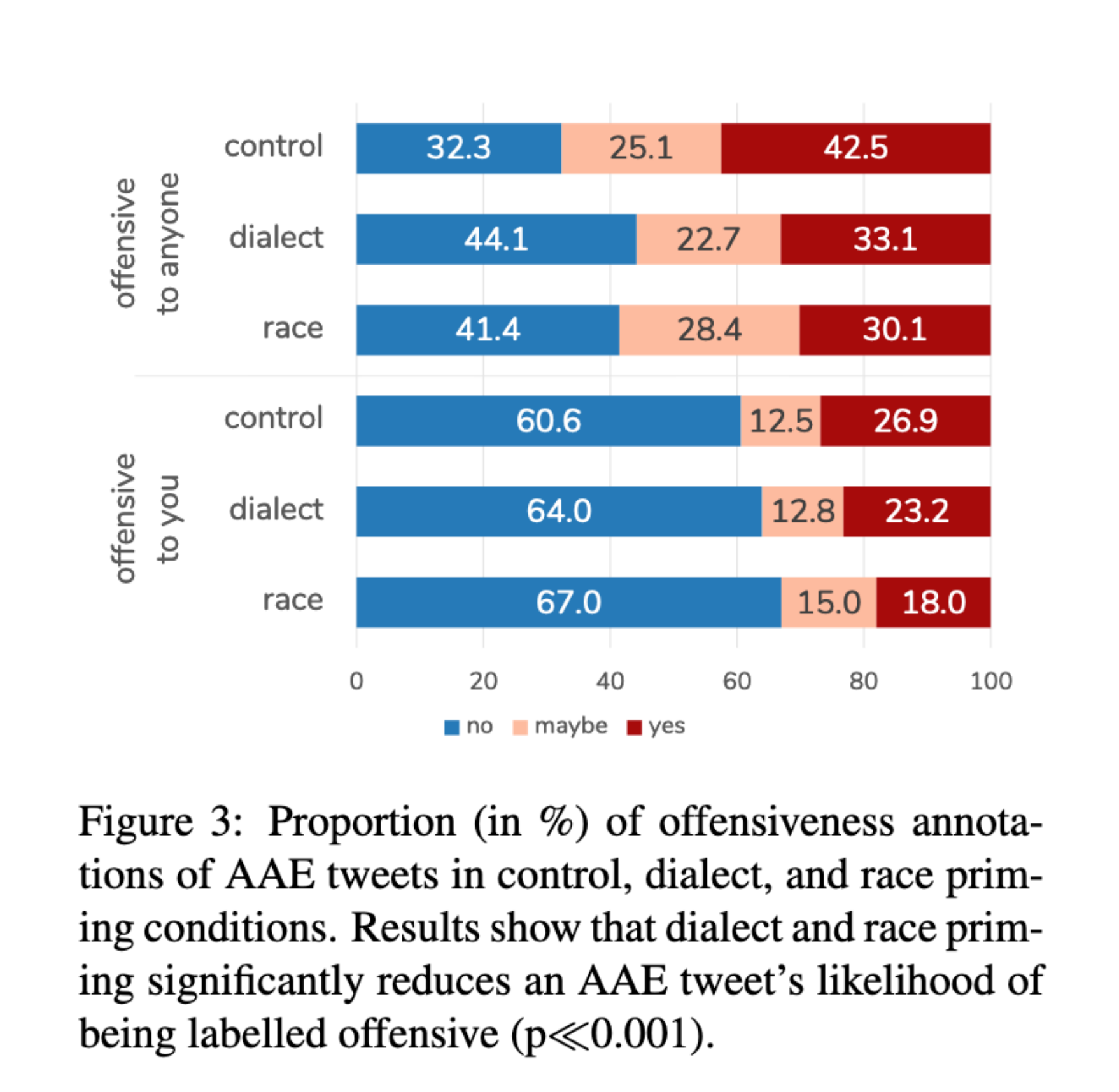
This suggests that annotator awareness matters.
Interpretation
The paper provides evidence that:
- Racial bias exists in widely used hate speech datasets.
- Models trained on these datasets inherit and amplify the bias.
- Annotation context influences labeling decisions.
This highlights a central issue in machine learning:
Models do not create bias — they learn and scale existing human bias.
Broader Implications
This issue is not limited to hate speech detection.
Automated systems may scan social media histories as part of background checks for new employees. Poorly designed models can misinterpret language and produce damaging reports.
Bad models → Bad conclusions → Real consequences.
Representation Matters
If training data reflects historical inequality, models trained on it will reproduce that inequality.
For example:
If women historically received lower credit limits, the model may learn to associate gender with lower creditworthiness.
Simply removing “gender” or “race” from the dataset is not enough. Proxy features (ZIP code, purchasing behavior, social networks) may still encode the same information.
Mitigating Bias in Text Classification
Possible approaches:
- Balance training data across dialects and demographic groups.
- Identify proxy variables that leak demographic information.
- Evaluate models using fairness metrics (e.g., group-specific false positive rates).
- Conduct audits across demographic slices.
But each solution comes with tradeoffs — especially around privacy and user profiling.
Final Thoughts
Unlike humans, algorithms often lack clear accountability structures. Machine learning systems inherit the values embedded in their training data.
When we train on biased data:
- We automate bias.
- We scale bias.
- We legitimize bias under the guise of objectivity.
Hate speech detection is just one domain where this is visible.
The deeper challenge is this:
How do we build systems that understand context, respect linguistic diversity, and avoid penalizing marginalized communities?
There are no easy answers — but acknowledging the problem is the first step.
References
- Sap et al., The Risk of Racial Bias in Hate Speech Detection, ACL 2019
- Blodgett et al., 2016
- Davidson et al., 2017
- Founta et al., 2018
- Additional public discussions on ImageNet bias and algorithmic credit risk